This Agreement represents a Service Level Agreement (“SLA”) between SYSTEMS OF RECORD, LLC (“Provider”) and (“Customer”) for the provisioning of cloud-based GIS services.
This Agreement outlines the parameters of all IT services covered as they are mutually understood by the primary stakeholders. This Agreement does not supersede current processes and procedures unless explicitly stated herein.
2. Service Description
The specific services covered by this SLA include:
Vector Tile API: Delivery of vector map tiles for web and mobile rendering.
Raster Tile API: Delivery of pre-rendered map images.
ArcGIS-compatible endpoints
Parcel Detail Lookups
3. Service Availability Guarantee
The Provider guarantees that the GIS Mapping Services will be available 99.9% of the time during any given calendar month.
3.1. Uptime Calculation
Availability is calculated as follows:
Availability % = ((Total Minutes in Month – Total Downtime Minutes) / Total Minutes in Month) * 100
Total Minutes in Month: The total number of minutes in the calendar month (e.g., 43,200 minutes in a 30-day month).
99.9% Allowance:This allows for approximately 43 minutes of downtime per month before the SLA is breached.
3.2. Definition of Downtime
“Downtime” is defined as a period of time where the Provisioned Web Service is unavailable to the Customer or returns a Server Error (HTTP Status 5xx) at a rate greater than 5% for consecutive requests over a 5-minute period.
Downtime is measured from the time the Provider is notified or becomes aware of the failure until the time the Service is restored.
4. Exclusions (SLA Carve-outs)
The following events do not count toward “Total Downtime Minutes” and are excluded from SLA calculations:
Scheduled Maintenance: Maintenance windows announced at least [48] hours in advance through direct email.
Force Majeure: Events beyond the reasonable control of the Provider, including acts of God, war, terrorism, riots, embargoes, acts of civil or military authorities, fire, floods, accidents, or strikes.
Customer Issues: Downtime caused by Customer equipment, software, or network connectivity issues (e.g., local ISP failure).
Suspension: Suspension of service due to violation of the Terms of Service (e.g., non-payment or abusive usage patterns).
5. Service Credits
If the Provider fails to meet the 99.9% Availability Guarantee in a given calendar month, the Customer is eligible for a Service Credit calculated as a percentage of the monthly service fee.
Monthly Uptime Percentage
Service Credit
< 99.9% – 99.0%
10% of Monthly Fee
< 99.0% – 95.0%
25% of Monthly Fee
< 95.0%
50% of Monthly Fee
Note: Service Credits are the Customer’s sole and exclusive remedy for any violation of this SLA. Credits must be requested within [30] days of the end of the month in which the service failure occurred.
The Land Records National Parcel Dataset is a comprehensive, standardized geospatial dataset aggregating parcel boundaries and associated land ownership and taxation attributes from various local jurisdictions across the United States. This document outlines the detailed description and technical specifications for this dataset.
2. Data Content
The dataset consists of geometric features representing parcel boundaries and a set of attributes that describe each parcel. Polygons representing the boundaries of individual land parcels for purposes of tax assessment for the jurisdiction in which they reside. These geometries are derived from digitized cadastral maps, surveys, recorded deeds, and legal descriptions of the parcel.
2.1. Schema Definition
Column
Type
Constraints
Description
lrid
STRING
REQUIRED
Universally unique ID (UUID) assigned to each parcel assigned by the Land Record database.
parcelid
STRING
REQUIRED
Parcel id assigned by the local administrative authority. AKA parcel number, APN, AIN, PID, and PIN. The format will vary.
parcelid2
STRING
NULLABLE
Alternate parcel id assigned by the local or state administrative authority. May be the same as parcelid if no alternate given.
geoid
STRING
REQUIRED
The full combined FIPS code of the jurisdiction in which the parcel resides (state fips + county fips).
statefp
STRING
REQUIRED
State FIPS code.
countyfp
STRING
REQUIRED
County FIPS code.
taxacctnum
STRING
NULLABLE
The assigned tax account number associated with this parcel / owner.
taxyear
INT64
NULLABLE
The year for which the provided tax assessments are levied.
usecode
STRING
NULLABLE
Land use code.
usedesc
STRING
NULLABLE
Description of the land use associated with this parcel.
zoningcode
STRING
NULLABLE
Zoning code associated with this parcel. These will vary in format.
zoningdesc
STRING
NULLABLE
Zoning description associated with this parcel. These will vary in format and length.
numbldgs
STRING
NULLABLE
Number of buildings located on the parcel. This includes primary residence as well as any accessory dwellings, garages, sheds, etc.
numunits
STRING
NULLABLE
Number of living units located on the parcel.
yearbuilt
STRING
NULLABLE
The recorded year that the primary building was constructed.
numfloors
STRING
NULLABLE
Number of stories/floors/levels in the primary building according to the local authorities.
bldgsqft
STRING
NULLABLE
Assessed area in square feet of the primary building.
bedrooms
INTEGER
NULLABLE
Number of known and assessed bedrooms in the main building.
halfbaths
INTEGER
NULLABLE
Number of known and assessed half bathrooms in the main building.
fullbaths
INTEGER
NULLABLE
Number of known and assessed full bathrooms in the main building.
imprvalue
BIGINTEGER
NULLABLE
Assessed value of improvements; typically this is the value of any and all buildings located on the parcel.
landvalue
BIGINTEGER
NULLABLE
Assessed value of the surface land only. Does not include value of buildings, agriculture, or subsurface minerals or water.
agvalue
BIGINTERGER
NULLABLE
Assessed value of any agricutlure or agriculture rights.
totalvalue
BIGINTEGER
NULLABLE
Total assessed value, i.e. landvalue + imprvalue + agvalue.
assdacres
FLOAT
NULLABLE
Assessor-specified acreage under assessment. May be different the calculated area.
calcarea
FLOAT
REQUIRED
Calculated area of the parcel geometry in square meters.
saleamt
BIGINTEGER
NULLABLE
Transaction amount of the most recent recorded sale that this parcel was a part of. Usually the parcel comprises the entire sale, but occasionally the sale amount can include other parcels.
saledate
DATE
NULLABLE
Transaction date of the most recent recorded sale that this parcel was a part of.
ownername
STRING
NULLABLE
Name of the recorded owner.
owneraddr
STRING
NULLABLE
Mailing street address of the recorded owner.
ownercity
STRING
NULLABLE
Mailing address city of the recorded owner.
ownerstate
STRING
NULLABLE
Mailing address state of the recorded owner
ownerzip
STRING
NULLABLE
Mailing address postal code of the recorded owner.
parceladdr
STRING
NULLABLE
Physical street address of the parcel.
parcelcity
STRING
NULLABLE
City in which the parcel is located.
parcelstate
STRING
REQUIRED
State in which the parcel is located.
parcelzip
STRING
NULLABLE
Postal code of the parcel.
legaldesc
STRING
NULLABLE
Legal description of the parcel; this is usually described in terms of lot numbers, plat numbers, book numbers, etc.
township
STRING
NULLABLE
Public Land Survey System (PLSS) township identifier.
section
STRING
NULLABLE
Public Land Survey System (PLSS) section identifier.
qtrsection
STRING
NULLABLE
Public Land Survey System (PLSS) quarter-section identifier.
range
STRING
NULLABLE
Public Land Survey System (PLSS) range identifier.
plssdesc
STRING
NULLABLE
Public Land Survey System (PLSS) full description.
book
STRING
NULLABLE
Plat book number or name.
page
STRING
NULLABLE
Plat book page number or name.
block
STRING
NULLABLE
Plat block identifier.
lot
STRING
NULLABLE
Plat lot identifier.
updated
DATE
REQUIRED
Date of last known update of the source data. If not specified by the source provider or if it is unknown, this field represents the date of most recent acquisition of source data.
lrversion
STRING
REQUIRED
Version of this dataset in the form YEAR.QUARTER, e.g. 2025.1 for the first quarter of 2025.
centroidx
NUMERIC
REQUIRED
x-coordinate (longitude) of geographic center POINT of the parcel in EPSG 4326. In rare cases the center may lie outside the parcel shape itself in the case of a ‘C’ shaped parcel.
centroidy
NUMERIC
REQUIRED
y-coordinate (latitude) of geographic center POINT of the parcel in EPSG 4326. In rare cases the center may lie outside the parcel shape itself in the case of a ‘C’ shaped parcel.
surfpointx
NUMERIC
REQUIRED
x-coordinate (longitude) of centermost POINT that is guaranteed to lie within the parcel’s surface in EPSG 4326. This point will never lie outside the parcel.
surfpointy
NUMERIC
REQUIRED
y-coordinate of centermost POINT that is guaranteed to lie within the parcel’s surface in EPSG 4326. This point will never lie outside the parcel.
geom
GEOMETRY
REQUIRED
MULTIPOLYGON of the parcel lot line boundary in EPSG 4326.
2.2. Notes on particular attributes
2.2.1. lrid
This column is guaranteed to be universally unique across the entire nationwide dataset, including within counties. It is an RFC 4122 UUID type that uniquely identifies each parcel across space, but not time.
Efforts are made in the landrecords database to maintain lrid lineage across vintages, so that a particular parcel maintains the same lrid over time as new versions of the dataset are produced. While this process is reliable, it is not perfect. Moreover, parcels regularly change shape as new digitization methods are used by assessors, and parcels are occasionally subdivided or joined to form entirely different parcels, and the lineage to the ancestor parcels is not always ascertainable.
2.2.2. usecode / usedesc
Localities define their own land use codes, but in most cases, these attributes are mapped to the LBCS (Land-based Classification Standards). In cases where the locality defines their own standard that does not align with LBCS, or the data is unavailable, usecode and usedesc may deviate from the LBCS.
2.2.3. zoningcode / zoningdesc
Like usecode, zoningcode is locality-specific. Unlike usecode, there is no nationally agreed-upon standard that all zoning codes and descriptions can be mapped to. Since specific zoning codes only have semantic value within the borders of a particular county (or city or other jurisdiction), zoning codes are kept in the format provided by the county, to the degree they are provided.
2.2.4. numunits / numfloors
This data is lifted directly from the source data when it is available, but it is often missing from source datasets. As a result, they are often estimated.
numunits is often estimated based on the number of mailing addresses associated with a parcel, provided there is at least one building on the parcel. Likewise, numfloors is rarely available in the source data, but can occasionally be estimated based on the known or modeled height of the main building. (The “main” building is whichever building on the parcel has the largest internal usable area measured in square feet).
For example if the building footprint is 1000sqft on the surface, has a total usable area of 1800sqft, a height of 21 feet, and is zoned residential, a reasonable conclusion is that this is a 2-story building, i.e. numfloors=2. The land records database will derive these data in circumstances such as this when there is a high degree of confidence.
2.2.5. parceladdr
Usually, the primary parcel address is that which, when written on the front of an envelope, would reach a mailbox located on the parcel grounds. But this is not always the case. Many localities assign addresses to parcels that no letter can ever reach. In these cases, the land records database prefers the physical address assigned by the local authority if it is made available.
Conversely, it is also the case that a single parcel can have many addresses, as in the case of an apartment building or commercial strip mall. In these cases, the address assigned is either 1) provided by the taxation or appraisal authority that has jurisdiction over the parcel, or 2) that which is closest to the centroid of the parcel, and in most cases, any unit number will be removed. The number of addresses associated with a parcel is shown indirectly in the numunits column of the parcel record.
2.2.6. legaldesc / plssdesc
A core historic function of the “county” unit of government is to record deeds and collect property taxes. Deeds are recorded by the county to indicate ownership of parcels, and as part of the deed is a “legal description” of the parcel in question.
Some counties publish the full physical legal description, which involves using the PLSS (Public Land Survey System) to describe the exact boundary and location of the parcel. Others describe simply the parcel’s filing location in the book of deeds, e.g. BOOK A2 PAGE 97 and its components will be stored in the columns book and page. Additionally, these recorded pages may have a map attached, and will be designated by block, and lot if available. The land record database does not discriminate between these various approaches, and will record the provided “legal description” in the legaldesc column, irrespective of the format.
On the other hand, the plssdesc will always contain a standardized PLSS description when it is available. 30 states utilize PLSS to describe the location and bounds of parcels, and its components separated into the columns for section, quarter section, range, and township. In the 20 states where PLSS is not used, plssdesc, range, section, and qtrsection will always be NULL.
2.3. Versioning and Updates
2.3.1. Update Schedule
The National Parcel dataset is updated quarterly on the first monday of each third month beginning January. Not all counties publish their source data at this interval, but all are checked by the land records database to pull, harmonize, and a merge updates if there are any.
2.3.2. Versioning
Each dataset includes the column lrversion which is set for each parcel and indicates the landrecords dataset release version. This is distinct and separate from the updated column which indicates the date of last source update or acquisition.
3. Data Processing and Standardization
3.1. Data Ingestion and Processing
Parcel data is collected from various authoritative sources, primarily county and municipal tax assessor offices, planning departments, and GIS departments. Data formats and source accuracy and update frequency vary widely.
3.2. Data Harmonization and Standardization
As of December 2025, the land record database maintains a catalog of data sources for over 3,200 US counties and all 50 states plus the District of Columbia and Puerto Rico. Each of these data sources are merged with others that represent the same county, and each of the combined table’s fields is mapped and typecasted onto the target schema described in Section 2.
3.3. Quality Control and Validation
Multiple quality control checks are performed:
Geometric Validation: Checks for topology errors (e.g., self-intersections, sliver polygons, gaps between adjacent parcels) and invalid geometries.
Attribute Validation: Checks for missing values in critical fields, data type conformity, and adherence to domain constraints.
Spatial Accuracy Assessment: Visual inspection and comparisons against high-resolution imagery and known reference points to identify significant spatial discrepancies. (This is where we use our human eyeballs and point them toward QGIS to see if anything looks “off”).
Temporal Consistency: Monitoring changes in parcel data over time to ensure updates are captured accurately.
Statistical Congruence: Many corrections are made based on statistical analyses of the datasets and the patterns of individual attributes and attribute categories.
4. Data Distribution
4.1. Source Data Precision
Geometric precision varies based on the original source data (e.g., surveyed vs. digitized from aerial imagery). There is no standardized or reliable way of ascertaining data accuracy from a particular source – the data provided by a county serves as the authoritative source of parcel/tax information for that county, and Land Records does not attempt to improve upon the county’s own methods of data collection and digitization.
4.2. Output Data Precision
The output dataset is snapped to a 1e-7 uniform grid, which results in a precision of around 1cm at most North American latitudes. Each vertex is snapped to the grid point which is closest to the underlying source data while preserving topology of the original geometry.
A large proportion of source data in the United States was collected and subsequently digitized against the NAD83 datum. The output datum however, is WGS 84. The typical, off-the-shelf transformation tools utilized by Land Records to transform geometries between these datums are usually accurate within a meter or so, but this varies by latitude.
100% accuracy in transforming between NAD83 and WGS84 would require taking into account the exact time at which the original data was collected, the methods used, and the subsequent tectonic plate drift that has occurred in the meantime. If this is a requirement for your use case, more details are available in this paper: Transformations between NAD83 and WGS84. See also this open-source implementation in C++: https://github.com/SonicScholar/trans4d-cpp.
4.3. Coordinate Reference System
The dataset geometries are always delivered in EPSG 4326 (SRID=4326). This maximizes compatibility with popular database engines, such as:
PostgreSQL (with PostGIS)
Google BigQuery
Snowflake
Amazon Athena
DuckDB
and other engines.
4.4. Published File Formats
The dataset can be delivered in one of many formats, so choose the one that best suits your database engine, use case, and other business and technical requirements.
4.4.1 Instant Downloads
The following formats are produced automatically with quarterly releases and are available for download immediately after purchase:
Shapefile (zipped)
GeoPackage
4.4.2. Custom Downloads
The following formats can be produced upon request:
GeoJSON (newline-delimited)
Geodatabase
pg_dump file
4.5. Published Web Services
The dataset is also made available to customers as OGC (WMS, WFS, etc) web services.
Fun fact: this is the same service that powers our data explorer! It is a MapLibre source configured like so:
We publish our coverage map as a web service for use in your applications. This is the same service that powers our public website at http://landrecords.us/products. It contains information about parcel coverage, as well as coverage for selected attributes.
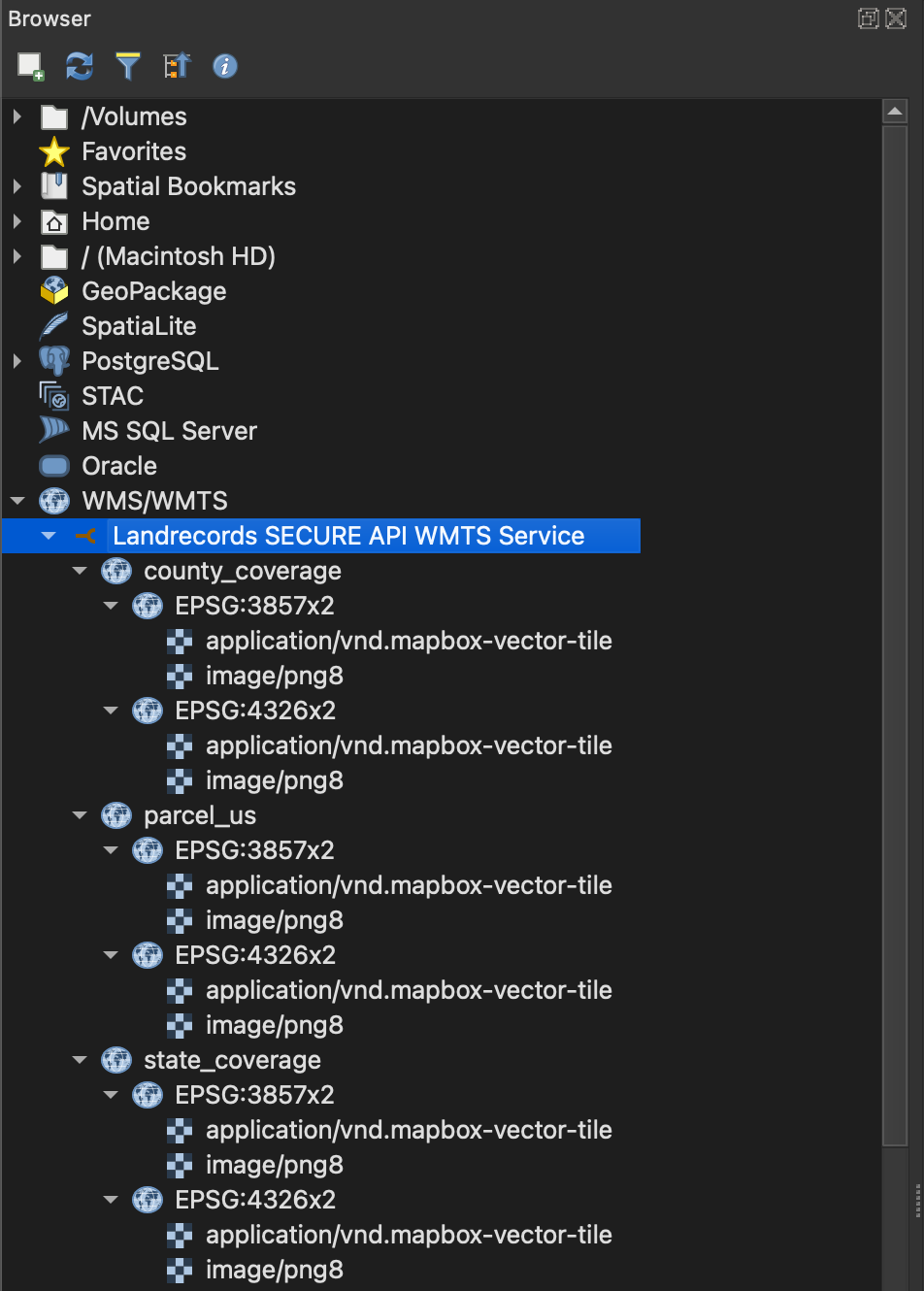
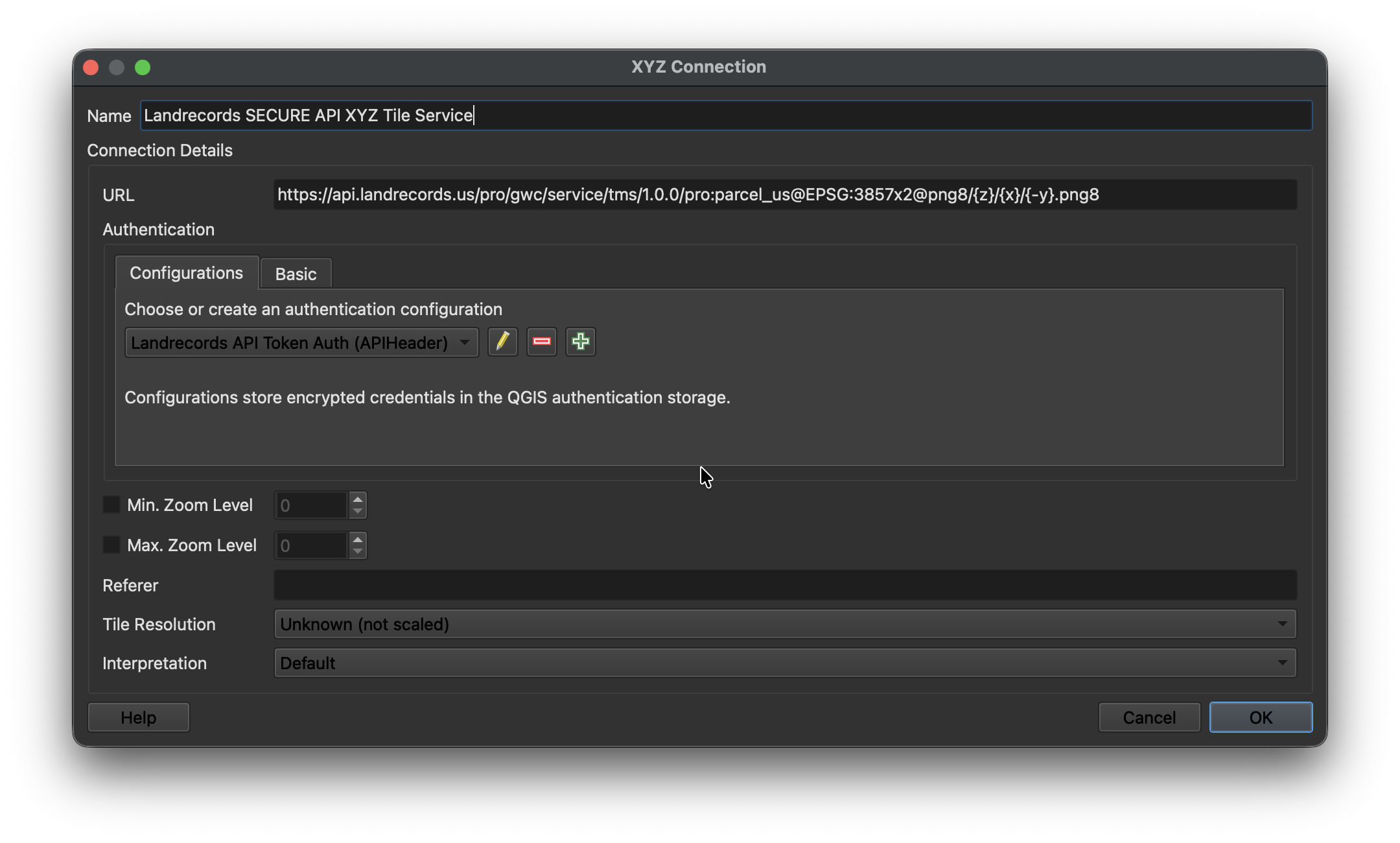
County Coverages: https://api.landrecords.us/pro/gwc/service/tms/1.0.0/pro:county_coverage@EPSG:3857x2@pbf/{z}/{x}/{y}.pbf?token=<TOKEN>
State Coverages: https://api.landrecords.us/pro/gwc/service/tms/1.0.0/pro:state_coverage@EPSG:3857x2@pbf/{z}/{x}/{y}.pbf?token=<TOKEN>
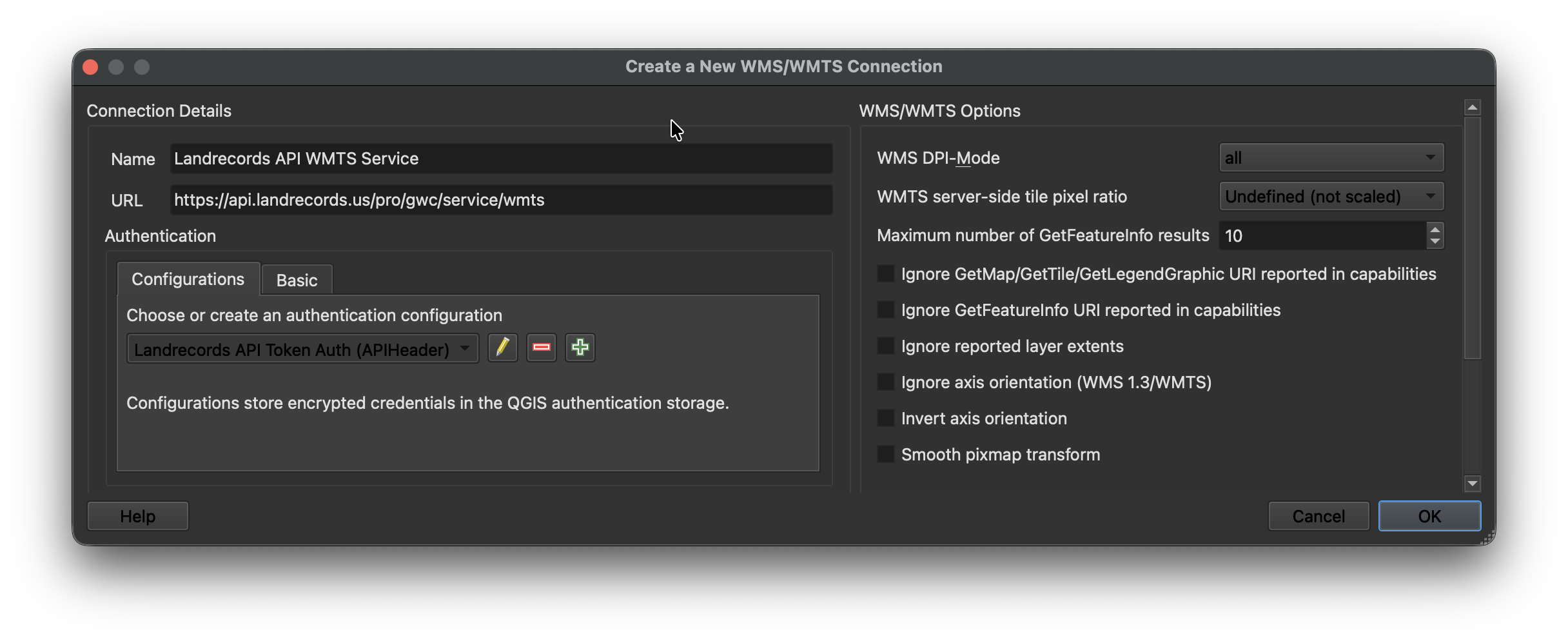
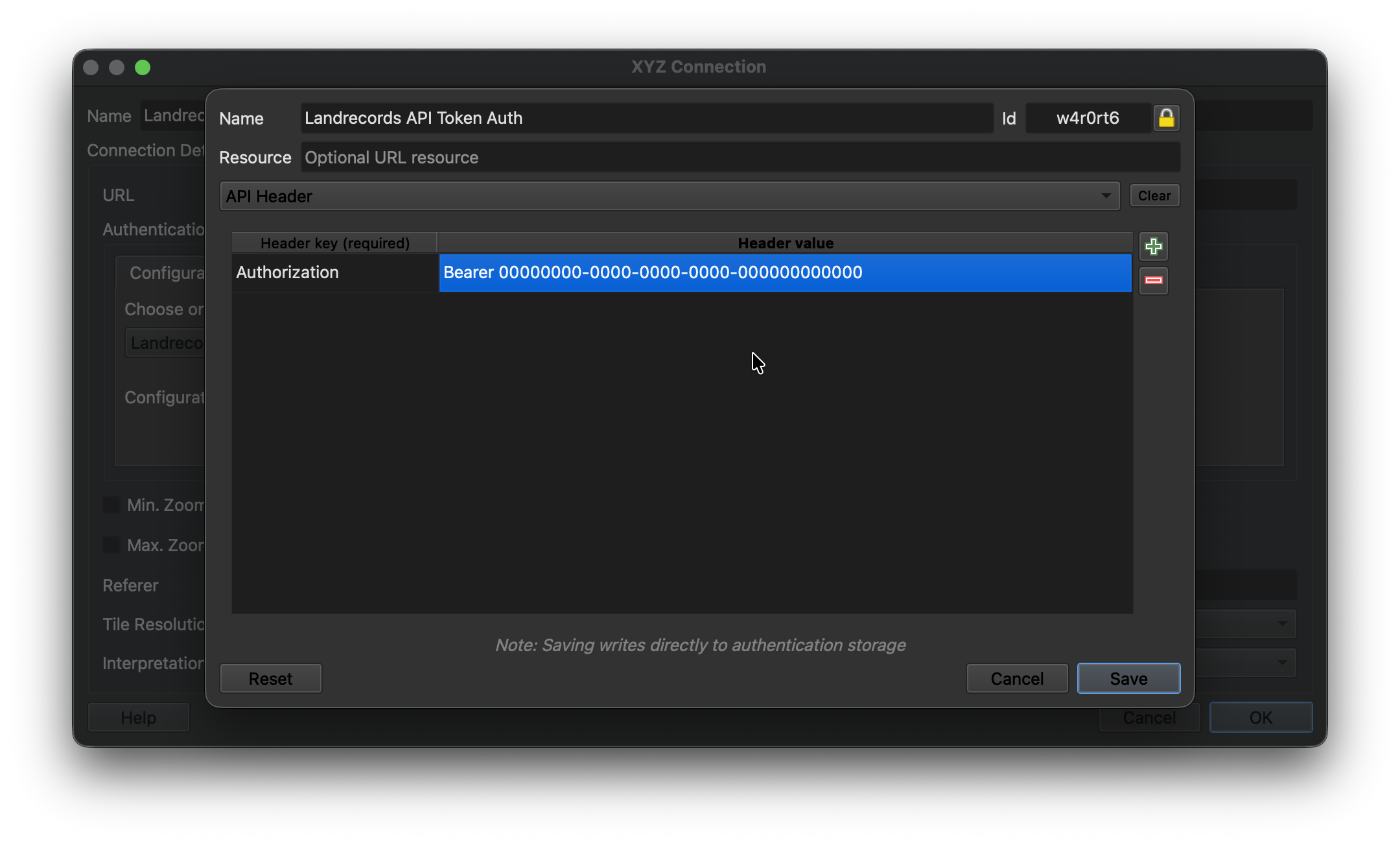
4.5.2. QGIS: Configure in a WMS/WMTS Connection
You can easily load the Nationwide Parcel layer into QGIS.
First, Create a New WMS/WMTS Connection.
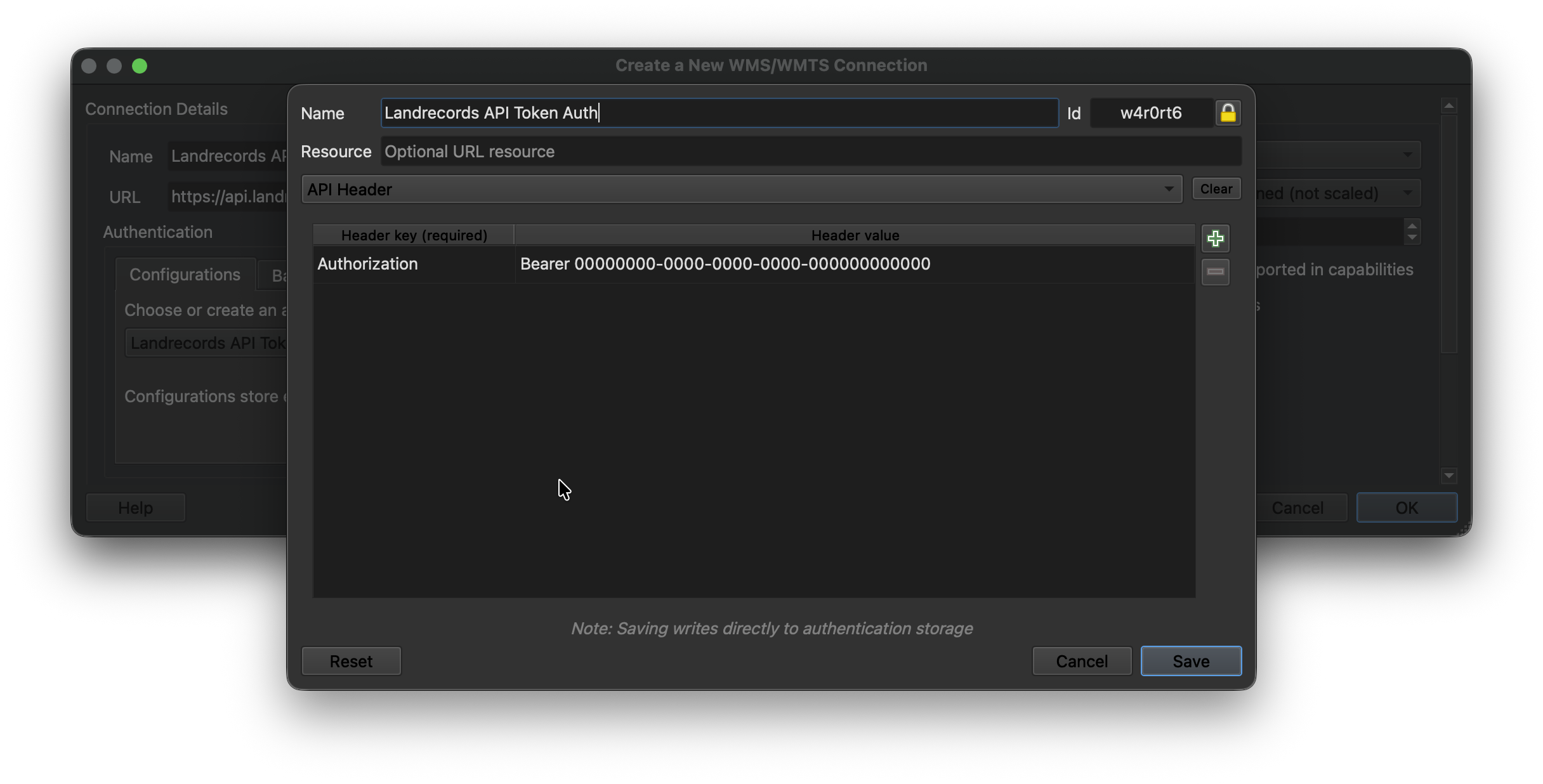
Then configure the new connection by pointing to the Landrecords API endpoint (api.landrecords.us), and setting the Authorization token provided after signup:
The per-county datasets range in size from very small (a few MB) to large (several GB) based on the size of the county and the number of attributes available. Likewise, the state datasets vary in size. The national dataset is quite large (100GB+ compressed, 250GB+ on disk), and performance challenges can arise even on modern database engines and modern hardware (as of 2026) and Cloud VMs.
Careful consideration needs to be made depending on your use case for the dataset, and what performance requirements you have.
5.1. Analytics Use Cases
For analytics-heavy use cases, BigQuery, DuckDB PostgreSQL + PostGIS are known to work well with this dataset. The more RAM you have the better: we recommend 128GB minimum.
At 155+ million rows, the dataset is on the upper end of what you’d normally expect a standard PostgreSQL installation to handle in an analytical usage mode, but it is known to work well with the right hardware and postgresql.conf settings.
No matter the use case, make sure the data is properly indexed / clustered on the geoid and geom columns.
5.2. Online serving use cases
For online map and query serving use cases, PostgreSQL is known to work well with this dataset.
If hosting on a single VM or physical server, the following hardware and database configurations are recommended:
5.2.1. Hardware Recommendations
At least a 4th gen Xeon or 4th gen Epyc processor with many cores
At least 64GB of the fastest RAM supported by your system
A fast SSD. NVMe drives designed for CDN content-serving with high read rates tend to work well.
5.2.2. Cloud VMs
Take special care to provision sufficient disk IOPS for usage of this dataset. This may require provisioning a larger-capacity drive than strictly necessary for data storage.
SSD persistent disk is strongly recommended.
Likewise for the hardware recommendations, at least 64GB of RAM is recommended for best performance for most use cases.
5.2.3. PostgreSQL configuration
Version 17+
Utilize partitioning where feasible, e.g. partition table by state or county.
create table lr_parcel ( … ) partition by list(geoid);
Frequently Asked Questions
How quickly is the parcel dataset download delivered?
For state and county dataset purchases, you will get access to the file download immediately after purchase.
For the nationwide dataset, you will receive an email with access instructions within 24 hours after your purchase.
What data formats do you support?
We support instant downloads for Parquet and Geopackage. If you need a different format, let us know! We’ve delivered everything from EWKT+CSV files to raw postgres data dumps. We’re here to support you.
Do you offer additional data layers other than Land Parcels?
We believe there’s power in focusing on doing one thing, and doing it well. We do not offer any other data layers at this time, but if there’s something you’d like to see added to the current dataset, please contact us and let us know.
Easily integrate our nationwide parcel grid into your application or website using our standards-compliant Web Map Service API. The data in this layer is updated quarterly.
This web service offers a direct, powerful way to access and visualize parcel boundaries and attribute data, providing a foundation for interactive geospatial applications.
Our flexible, pay-as-you-go access model is designed to suit various usage levels, from occasional parcel detail lookups to supporting low-volume public or private mapping applications.
Service
Rate
Per 1,000 Parcel Detail Requests
$40
Per 10,000 Tile Requests
$25
This pricing model ensures you only pay for what you use, with no minimums and no commitments.
Included Services
The table below outlines the core services currently supported by our Web Feature Service API.
Service
Included
Description
Tiled WMS Service
Yes
Standard Tiled WMS Service, also known as WMTS (Web Map Tile Service)
Parcel Detail Queries
Yes
Allows retrieval of specific attribute data for individual parcels.
Getting Started
You can already integrate our free, public WMS service into your application today: https://ows.landrecords.us/public/wms. This is the same service that powers our product map!
The secure, paid service removes the “landrecords.us” watermark from map tiles, and enable the ability to query parcel details by point (i.e. clicking on a parcel).
To access the service, you will be provided an API key and usage instructions after checkout.
Like all great ideas, the landrecords parcel dataset came from a place of irritation with the status quo.
I’m sorry, you want how much??
In 2019, I set out to build a natural hazard map that incorporated NFIP flood risk data, terrain characteristics, and historical weather patterns to produce a risk profile for a property. I was confident that developing the mapping application, statistical analyses, and machine learning were within my capabilities. So as the first step in this project, I set out to gather the required data to power the application.
Nationwide digital elevation models for terrain analysis — a lot of data, but readily available.
Nationwide NFIP flood zones and historical claims data — no problem.
Nationwide parcel boundaries and property attributes — I’m sorry, you want how much?
I was stunned, and my project was stuck. For their parcel datasets, each of the vendors I talked to wanted more than a year’s salary for most GIS analysts. (One company, known as CoreLogic back then, wouldn’t even talk to me). What I thought was the most straightforward of all the datasets turned out to be the most expensive and difficult to acquire.
2020: I started with the A’s
I didn’t have that kind of money, so I started collecting some data myself. My hope was to gather enough data to power my application for a local area. I had no ambition or desire to create a nationwide dataset.
My first parcel dataset inventory spreadsheet
Manually visiting county websites and looking for parcel data is not a fun task. I started a spreadsheet to record how I got the data and where it came from. A lot of counties don’t post their data publicly, so I sent quite a few emails.
And after I had collected enough data for a dozen or so counties, I had a new problem: none of this data was standardized in any way. Different file formats, table schemas, column types, naming conventions — everything was different from everything else. I tried to use jellyfish to automate some of this, but this failed, and eventually I settled on hard-coding some manual transformations to turn it all into a unified format.
This approach doesn’t scale, of course. Manually visiting websites, clicking buttons, downloading files, ETL-ing those files into a database, doing a bunch of harmonization, etc. wasn’t the project I signed up for. I realized I would have to settle for supporting just a few counties in my application.
2023: The AI revolution
I long suspected that if AI ever took off, computer programmers were going to be most at-risk. I reasoned that long before an AI could fully understand human language, it probably would first figure out computer languages. And my day job working at a big Cloud provider gave me some insight into what these new language models (LLMs) were capable of.
Despite the “hallucinations”, these models appeared quite good at programming. In particular, they excelled at understanding the relationships among unstructured and semi-structured data.
I remembered a few years ago I tried and failed to do something similar with parcel data to unblock my property hazard project. I wondered if these new LLMs could help.
I worked in the Cloud business, so naturally I thought to use one of the leading LLM APIs, like Gemini or ChatGPT.
But I quickly ran into another cost issue: I needed the LLM to understand the datasets and schemas of thousands of data sources. Not just once, but every day or week or month in order to maintain the most recent data and keep the mappings up-to-date. And many of these data sources get thrown away because of low data quality, or they are outdated, or they are just the wrong kind of dataset entirely.
I quickly ran up an AI inference bill of $800+ just from a one-time import of only a few hundred counties. Extrapolating out, I would need to budget many thousands of dollars each month to leverage this new technology. I tried a few different Cloud services, and always ran into the same issue: by the time I paid my ever-increasing cloud bill, I would have been better off selling my house and giving the money to Regrid!
Another option is to own some of the hardware. I already ran my own database servers for a similar reason: inter-component bandwidth is a scarce resource, and the high cost of Cloud VM IOPS makes it expensive to run ultra-high-performance databases in the Cloud. (and the new Xeon 6 CPUs were selling at a big discount). The scarcity of high-powered GPUs placed a similar premium on LLM inference.
I got a bit lucky on this one: my existing database server happened to have four unused double-width PCIe slots.
I got in touch with an NVIDIA distributor, and they were glad to sell me a stack of high-powered NVIDIA Hopper GPUs (which I’ve since upgraded to Blackwells) that could run some of the largest most sophisticated models available.
This decision — unlimited local processing and inference at a fixed cost — was the key to unlocking the rest of this story.
A stack of NVIDIA Blackwell GPUs sitting on top of my database server
Not everything can run in a local datacenter, of course. Since starting, much of the compute capacity I’ve added has been Cloud-based. Google Cloud hosts key components of the storage and API serving infrastructure, and Fastly is used as a CDN and Application Firewall.
But the core dataset acquisition, harmonization, and publishing still takes place on custom-built, state-of-the-art self-hosted hardware.
2024+: Launch Time
About a year ago, when I reached 95% coverage of the United States, I knew I had something special.
With 100% coverage in sight, I started thinking about how I would launch it as a product. I needed the usual suspects: a website, a delivery mechanism, some infrastructure to replicate and backup everything, and a whole lot more automation that the current system had.
The core system today based on Ray, Docker, Python, and PostgreSQL, is almost entirely automated. These days I spend much of my time working on increasing coverage of additional property attributes.
I also wondered how the established private equity-owned incumbents Regrid and CoreLogic would react. I think their prevailing cost structures will not permit them to operate the way I am, and I do not see a path for them to get to where I am today. I think the only way for them to do what I’ve done is to start over. In that sense, I have a substantial head-start.
So, how will these companies respond to a new competitor offering drastically lower prices?
My guess? Not well. Private equity is not known for their sportsmanship, let’s say. But I’ve made it this far, and so I’m pressing forward.
So, who are we?
Landrecords is the name of the product, Systems of Record LLC, a Virginia corporation, is the name of the company. It is a founder-led and independently-owned company with the mission to make property data accessible to everyone. My ambition is to do exactly one thing, and do it better and cheaper than anyone else. And to give back to important community projects that have helped along the way.
I don’t pretend to be a big company, and I am proud to offer the lowest-cost nationwide parcel dataset of the United States with nearly 155M parcel records.
Thank you to all of our customers and early testers whose feedback and analysis has made it possible to deliver the product we have today.